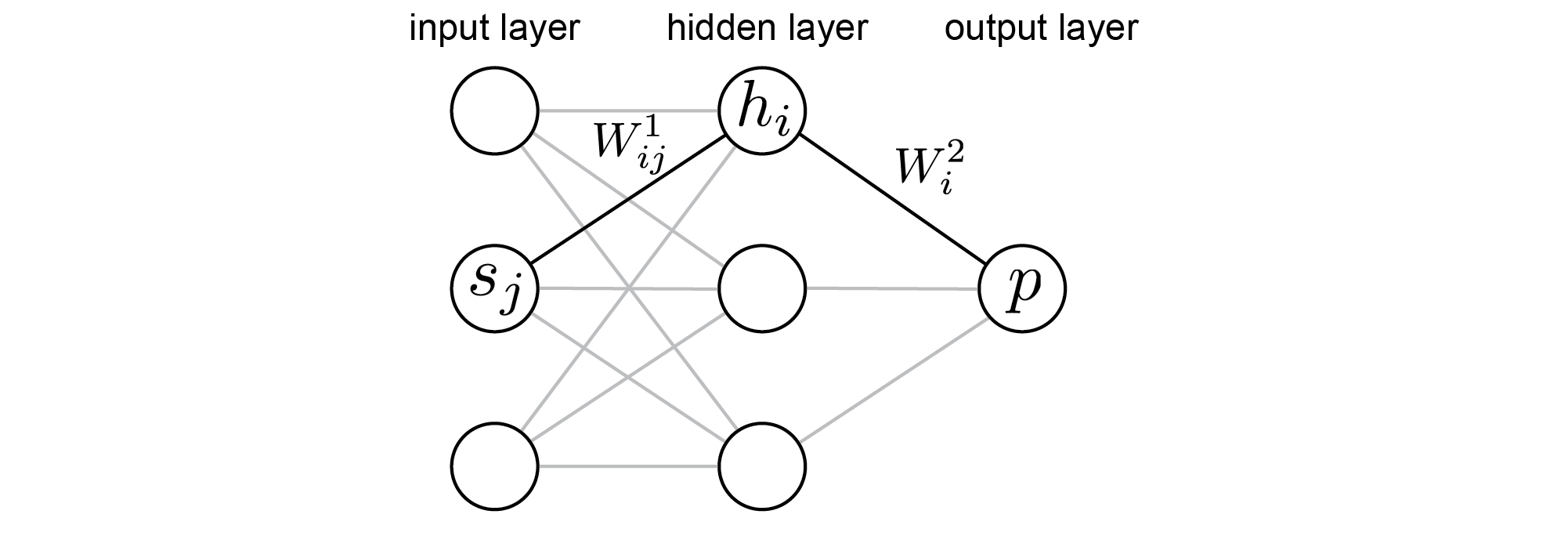
Backward propagation¶
Having set up a model for the policy we may now compute its gradient, $\nabla_W \log \pi( a\, | \, s)$. Considering the two possible values of $a$ separately, and using the chain rule of differentiation, one may show that the matrix representing the gradient of the policy with respect to $W^2$ (the weights coming out of the second layer of the policy network) is
\begin{equation}
\nabla_{W^2} \log \pi( a\, | \, s) = \delta^3(s,a) h^{\text{Tr}}(s)
\end{equation}
where Tr denotes transpose. The first factor on the right-hand side is defined by
\begin{eqnarray}
\delta^3(s,a) & = & y(a) - p(s) \\
y(a) & = &
\left\{
\begin{array}{cc}
1 & \text{ if } a = \uparrow \\
0 & \text{ if } a = \downarrow
\end{array}
\right. .
\end{eqnarray}
and measures the sensitivity of $\log \pi(a \, | \, s)$ to changes in the weighted input to the output neuron.
We may now compute $\nabla_{W} {\cal L}(\tau)$ for a sample trajectory $\tau = \{ s^0, a^0; s^1, a^1; \ldots ; s^T \}$ as:
\begin{equation}
\boxed{
\nabla_{W^2} {\cal L} = \left(\hat{\delta^3}\right)^{\text{Tr}} H
}
\end{equation}
where
\begin{equation}
H =
\left[
\begin{array}{rcl}
\cdots & h^0 & \cdots\\
\cdots & h^1 & \cdots\\
& \vdots & \\
\cdots & h^T & \cdots\\
\end{array}
\right],
\end{equation}
and the notation $\cdots h^t \cdots$ indicates that the vector of hidden-layer activations at time $t$, $h^t$, should be written as a row vector. Also,
\begin{equation}
\hat{\delta^3} =
\left[
\begin{array}{c}
\delta^{3,0} \, R^0_{\text{disc}} \\
\delta^{3,1} \, R^1_{\text{disc}} \\
\vdots\\
\delta^{3,T} \, R^T_{\text{disc}}
\end{array}
\right],
\end{equation}
where $\delta^{3,t} = \delta^3(s^t, a^t)$.
A similar but more involved calculation yields
\begin{equation}
\boxed{
\nabla_{W^1} {\cal L} = \left(\hat{\delta^2}\right)^{\text{Tr}} S
}
\end{equation}
where
\begin{equation}
S =
\left[
\begin{array}{rcl}
\cdots & s^0 & \cdots\\
\cdots & s^1 & \cdots\\
& \vdots & \\
\cdots & s^T & \cdots\\
\end{array}
\right]
\end{equation}
is the matrix formed by vertically stacking the states at each time point, with each state written as a row vector.
The error term $\hat{\delta^3}$ is 'back-propagated' to a similar error term,
\begin{equation}
\hat{\delta^2} = \left( \hat{\delta^3} \otimes W^2 \right) \odot u(H),
\end{equation}
associated with variations in inputs to the hidden layer. In this formula,
the Outer Product is defined by
\begin{equation}
(u \otimes v)_{ij} = u_i v_j,
\end{equation}
and the Hadamard Product by
\begin{equation}
(A \odot B)_{ij} = A_{ij} B_{ij} .
\end{equation}
The function $u$ is the Heaviside function,
\begin{equation}
u(h) =
\left\{
\begin{array}{cc}
0 & h = 0 \\
1 & h > 0
\end{array}
\right. ,
\end{equation}
and comes from back-propagating through ReLUs in the hidden layer. It tells us that, should a hidden neuron ever become zero (dead) at all time points in a trajectory, then $\nabla_{W^1} {\cal L}=0$ for all the associated incoming weights $W^1$, which therefore do not change when a gradient descent update is performed. To the extent that the neuronal activations experienced during the trajectory were typical, the hidden neuron is therefore destined to remain dead, and no learning associated with this neuron is possible. This is a well-known problem associated with ReLU neurons. It can be monitored by reporting the number of dead neurons as training progresses, and mitigated by reducing the learning rate $\alpha$ should the number of dead neurons become unacceptably high.